Business Intelligence Strategy: Best Practices for Building an AI-Ready BI Architecture
Business intelligence (BI) has rapidly evolved. There was a time when BI strategy meant choosing a reporting tool and defining key performance indicators (KPIs). With large language models (LLMs) coming online, BI teams must now ask different questions about how insights should be delivered, data should be accessed, and queries should be generated.
Old-school BI workflows typically get stuck at certain stages because business users have to either wait until the dashboards are built or rely on an analyst who knows how to write SQL. These blockers impede swift decision-making and do not allow teams to iterate quickly on new questions.
With LLMs that translate natural language into queries that return context-aware answers, BI goes from static dashboards to dynamic natural language interfaces for insight delivery into the enterprise in a more accessible, contextual, and scalable way. To get the most out of these changes, your BI strategy needs to be improved, not just in terms of the user interface but deep inside your data architecture, metadata layers, and access governance.
This article describes six actionable, technically grounded best practices that can help data and business intelligence (BI) teams build LLM-ready, scalable, secure, and adaptive feedback-driven BI strategies.
Summary of key business intelligence strategy best practices
The following six best practices outline how a modern business intelligence strategy needs to evolve in support of AI and LLM-driven workflows. Each practice focuses on bringing architecture, governance, and access into alignment so that BI systems can be scalable, trusted, and insight-driven.
Understand the relationships among business intelligence strategy, data strategy, and technology
A business intelligence (BI) strategy aligns data and analytics programs with business objectives. It is a subset of a broader data strategy that outlines the organization's wider approach for the management and use of data.
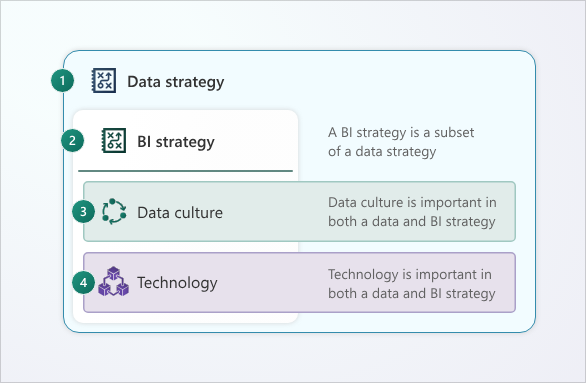
The relationship between BI and enterprise data strategy determines whether your insights are consistent, scalable, and trusted or fragmented and contested. According to Microsoft’s Power BI guidance, a good business intelligence strategy should translate the objectives of your data strategy into operational tools, systems, and workflows. Picking the right tools, systems, and workflows requires understanding emerging technologies. The rapid development of AI needs to be incorporated into your BI strategy.
Text-to-SQL technology has been integral to BI because it allows non-technical users to interact directly with data and develop an organization's data culture. LLMs have advanced text-to-SQL systems to enable natural language inputs to be accurately translated into SQL queries.
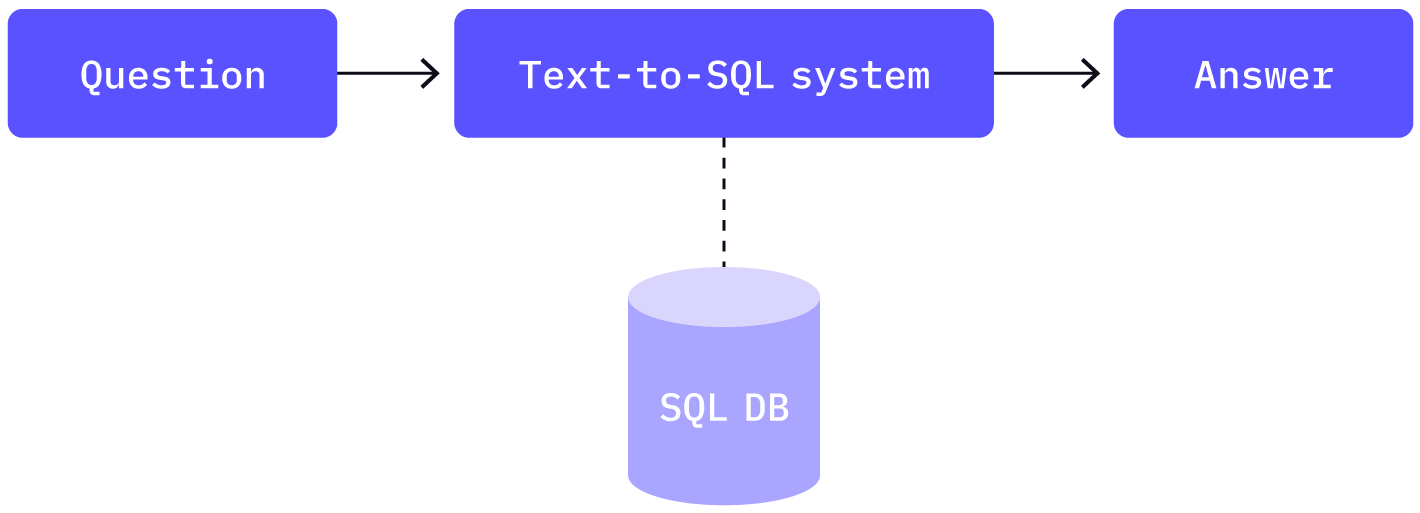
There are two main challenges in applying LLM-based text-to-SQL systems that a business intelligence strategy needs to address:
- Data maturity: Data needs to be accessible to the AI system, but this does not mean you need “perfect data” before leveraging AI. A data maturity framework will help you assess your organization’s AI readiness for business intelligence.
- Business context: An off-the-shelf LLM will not have been trained on your business terminology and processes. Retraining LLMs is expensive, so it makes more sense to use semantic/context technology to provide the LLM with definitions to help understand a user’s question in the correct business context. State-of-the-art semantic/context layers can learn from your organization’s unstructured data source and user feedback.
Use a data maturity framework to assess AI readiness
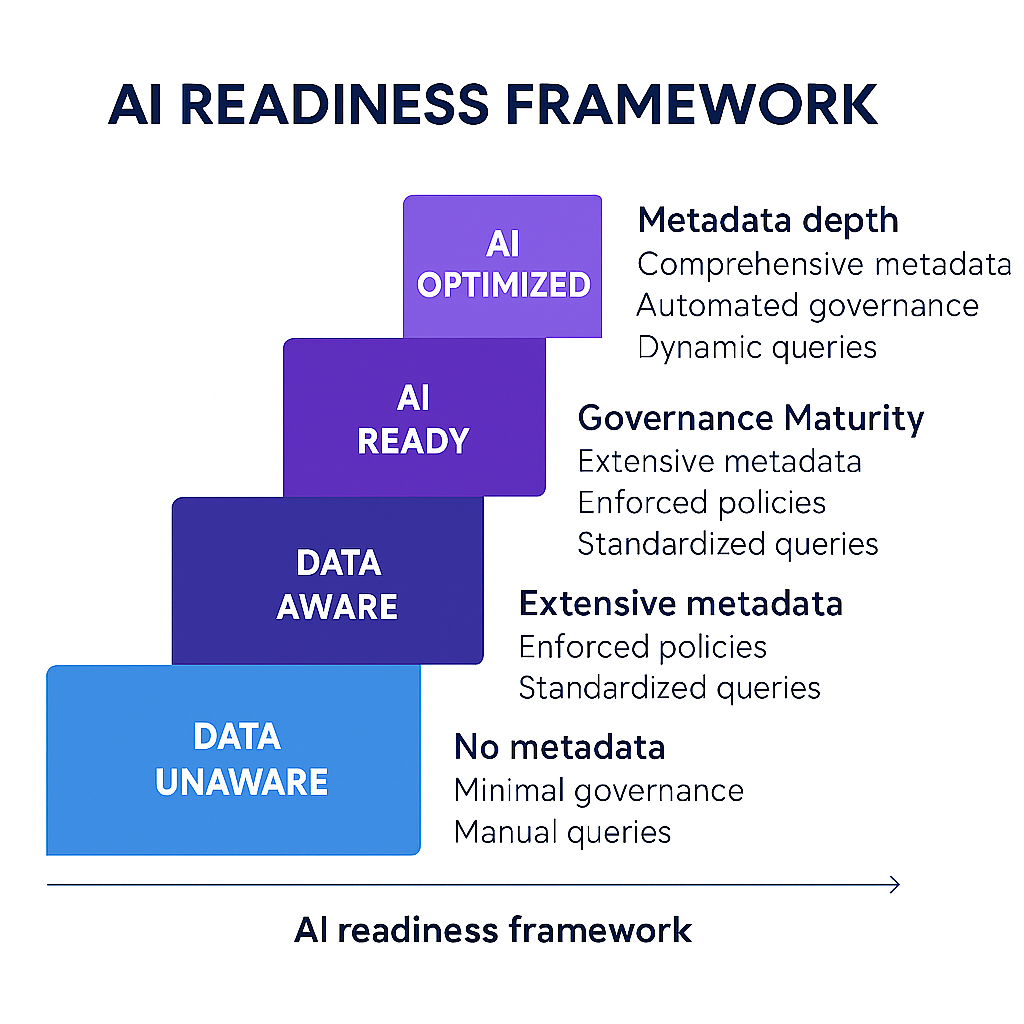
An advanced BI strategy cannot exist without appropriate data maturity. As LLMs start taking their rightful place in analytics workflows, data systems increasingly need to be high quality and complete while still maintaining observability.
A maturity framework stands precisely in the middle of this. The WisdomAI AI Readiness Framework describes four AI readiness stages to use as benchmarks by BI leaders:
As the table shows, each stage represents a step change in maturity:
- Stage 1 (Optimized) is the ideal state of well-governed, well-understood data that an AI can easily navigate.
- Stage 2 (Refined) is where most things are in order, but perhaps a few legacy issues or minor inconsistencies persist.
- Stage 3 (Fragmented) suggests an organization that has made some efforts but still suffers from silos and inconsistency. A lot of the work is done manually by experts to bridge gaps.
- Stage 4 (Chaotic), as the name suggests, is an environment where deploying an AI would likely fail or produce misleading results.
Most corporations fall between stages 2 and 3, where the semantic/context layer's role is critical to AI's success.

{{banner-large-3="/banners"}}
Develop a context layer for LLMs
Context layers are abstraction layers that map business-friendly terms such as “churn,” “revenue,” or “active user” onto underlying data models and warehouse logic. Without a context layer, companies may find, for example, one metric defined in three ways in five dashboards. As teams adopt LLM-powered analytics, the inconsistency risk grows further and includes hallucinated joins, incorrect filters, or mismatched KPIs.
A context layer resolves these problems by serving as a governed abstraction that maps business terms to the underlying SQL logic, dimensions, and filters. When implemented well, it allows humans and machines to communicate in the same analytical language without retyping queries in every tool.
Teams must agree upon semantic definitions across platforms. For example, are data models version-controlled and accessible to BI authors? This is necessary to encourage the reuse of standard logic across teams, discourage “shadow metrics,” and ensure consistent behavior over time. For example, if a user had a transaction in the last 30 days, he or she was considered active on the platform; an umbrella definition would be incorporated into a context layer that a dashboard, an LLM, or a metrics API could invoke.
Why the context layer matters for LLMs
The context layer acts as scaffolding that LLMs need to produce SQL that is reliable, secure, and business-aligned. Instead of hallucinating field names or misinterpreting user prompts, LLMs can also directly call the context layer via APIs, using metadata as a guide. This ensures that both human and agent users always refer to the same trusted definitions. Over time, this feedback (e.g., users clarifying this metric) can further refine the mappings, making them even more accurate and explainable.
When designed and governed rightly, the context layer can be made the base for both self-service BI and AI-driven insight delivery. Previously, semantic layers depended on established schemas and rules, resulting in a lack of flexibility when accommodating schema modifications, integrating new data sources, or adapting to changing business needs.
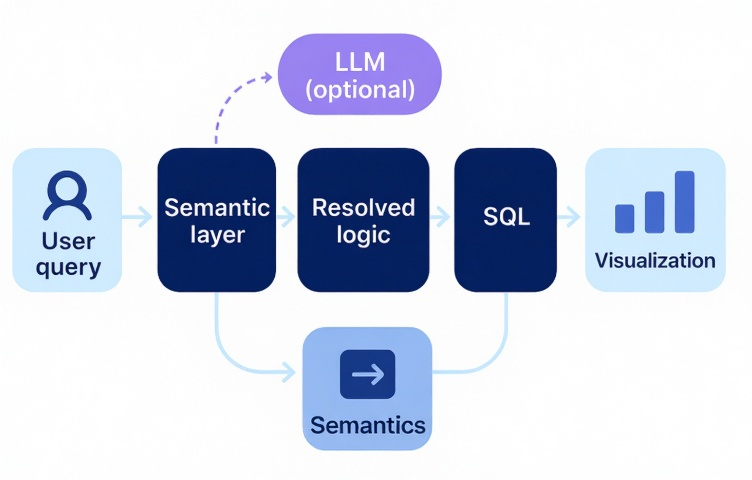
The design of semantic layers for structuring data in BI dashboards limits their ability to interpret natural language queries. This is particularly evident when such queries depend on domain-specific context or specialized business terminology. To overcome these limitations, a dynamic enhancement of the conventional semantic layer specifically tailored for generative AI applications, is made by the context layer.
Core components of a context layer
A well-thought-out context layer includes a “business term registry” that defines measures and dimensions with their synonyms and contextual meanings. It is important to have a proper and standardized vocabulary for all metrics of interest, such as “bookings” and “loan-to-value (LTV) ratio,” so that teams are all talking the same language.
This registry is accompanied by "reusable SQL logic blocks": keyed fragments for queries enabling a uniform way of referring to terms such as “churn rate” or “monthly revenue.” These modularized blocks are used to create JOIN paths, WHERE clauses, and time filters, ensuring consistent query generation.
To maintain transparency, the context layer should contain model lineage and metric dependencies, enabling teams to follow any output back to its derivation. This helps trace from the semantic terms to the underlying tables and columns in the warehouse, ensuring transparency and trustworthiness.
It should also have role-based access control mappings to guarantee security by preventing users from querying any metric outside what their permissions allow.Governance rules specifying who can query what and with what granularity scale are given as user roles in tools.
Understand the importance of metadata and context for LLMs
Most BI systems were never created to support AI agents or LLMs. For an LLM to provide accurate, useful, and governed insights, it needs to work on well-structured, well-described data, not just rows sitting in a warehouse.
A semantic/context layer bridges raw data and the LLM. LLMs depend on this surrounding metadata and context, such as schema definition, query patterns, and business logic, to generate accurate queries. The depth of metadata available to the LLMs determines the AI readiness of your organization’s data.
Metadata describes what each column means, how it relates to other fields, and where it derives from. Joining this with lineage and context makes metadata a bridge between human language and machine-executable logic.
Included in that metadata and context are the structure of the tables, the meaning of their columns—e.g., with “churn_date,” are we referring to cancellation or inactivity?—and where they provide an exact calculation to some business metric.
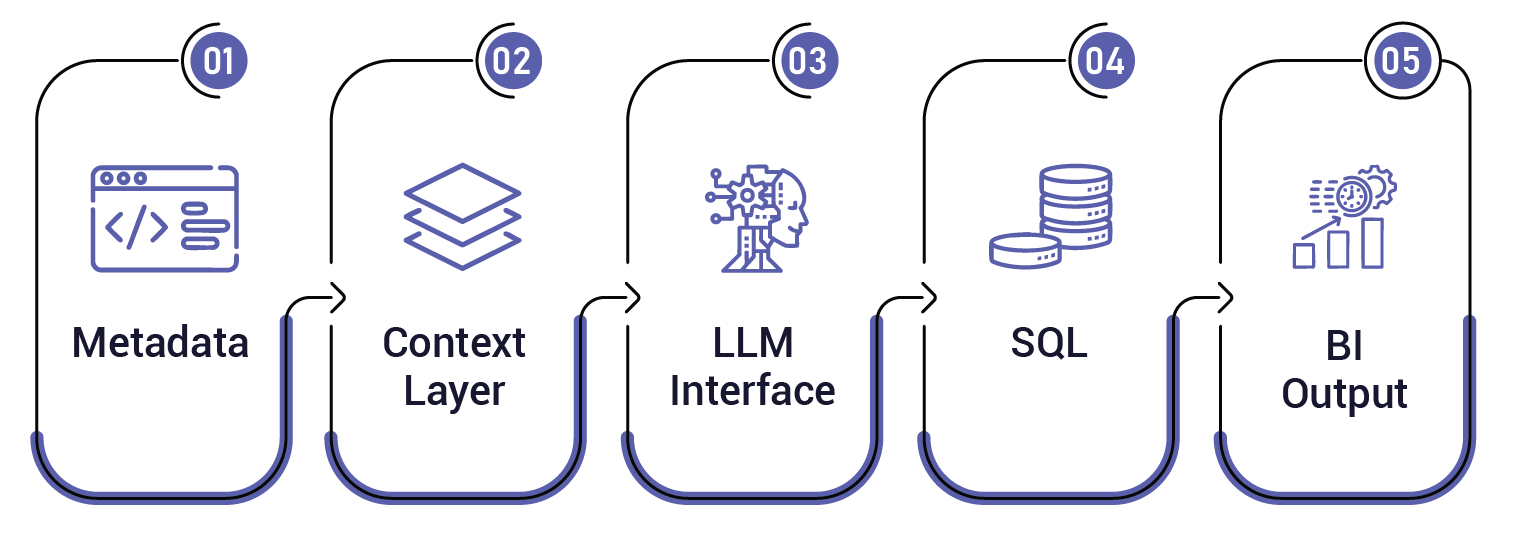
For example, if there are no column descriptions, sensitivity tags, or semantic mappings, an LLM that is given the query “What’s our churn rate for Q1?” has no way of resolving whether “churn” refers to subscription cancellation, contract downgrade, or support disengagement.
There are four key types of key metadata for LLM integration:
- Business definitions: For example, “What does ‘active user’ mean in your organization?”
- Column-level tags: PII, financial, calculated fields
- Data lineage: What tables or systems produce each field?
- Semantic context: How KPIs relate across domains
Metadata and context best practices
Structured metadata allows an LLM to do more than just pattern matching, enabling natural language-based, reliable, governed, and explainable BI queries. For this, your metadata/context layer must be developed, presented, and maintained with intent:
- Have one source of truth for controlling definitions and relationship types.
- Allow controlled access to business terms and lineage for query generation.
- Keep updating definitions by tagging fields that are most commonly misunderstood or high-error-prone areas.
- Use standards such as ISO for date labels, currency codes, or timezone suffixes to limit ambiguity.
Democratize data access with LLMs
One of the most promising transformations in BI is that non-technical users can now query enterprise data using natural language. However, this democratization only works when built upon structured metadata, a solid context layer, an intuitive UI, reasonable governance, and authentication through a known identity provider.
Why a good UI requires more than just APIs
An overwhelming majority of text-to-SQL systems offer API endpoints that theoretically can be queried within the SQL itself, being extremely lengthy and unforgiving. Non-technical users, especially those coming from dashboard-based tools, seek conversational interfaces that are intuitive, responsive, and forgiving.
A good UI not only renders outputs but can also scaffold the user's question, identify potential ambiguities, and furnish context as to what the LLM is permitted to consider in its answers. Note that the user interface is a differentiator, not merely a layer. A good UI will help users craft better prompts, show available fields, and explain the query scope.
Secure architecture for LLM-based BI access
Large language models (LLMs) parse questions such as “How did sales perform in the Northeast last quarter?” and generate the corresponding SQL. However, translation is no longer the bottleneck; the problem becomes ensuring safety in the right context and scalability without compromising trust, governance, or performance.
For example, a marketing manager should not be permitted to access customer PII even if the question is seemingly harmless (“List the top 10 VIPs by spend.”). Role-based access filters and query validators will help to prevent accidental overreach.
To securely allow natural language access to business data, your architecture should include the following components.
Layer security; don't layer post hoc reviews
Make sure that the query formation is passed through multiple real-time gates, such as permission checks, semantic validation, and metadata context enforcement, instead of just reviewing LLM queries before execution. These ensure that strong role-based access controls are applied so that users can only gather data to which they are explicitly allowed. Query validation can come next, filtering out queries that are incomplete, ambiguous, or risky—the kind of query that can unintentionally join sensitive data sets.
Outputs are then controlled and flagged if they deviate from expectations or if the metrics differ from yet-accepted definitions. For the required trail, in the end, maintain an audit trail of each prompt, query, and result so that identification can be traced back to specific users' decisions and actions through compliance verification.
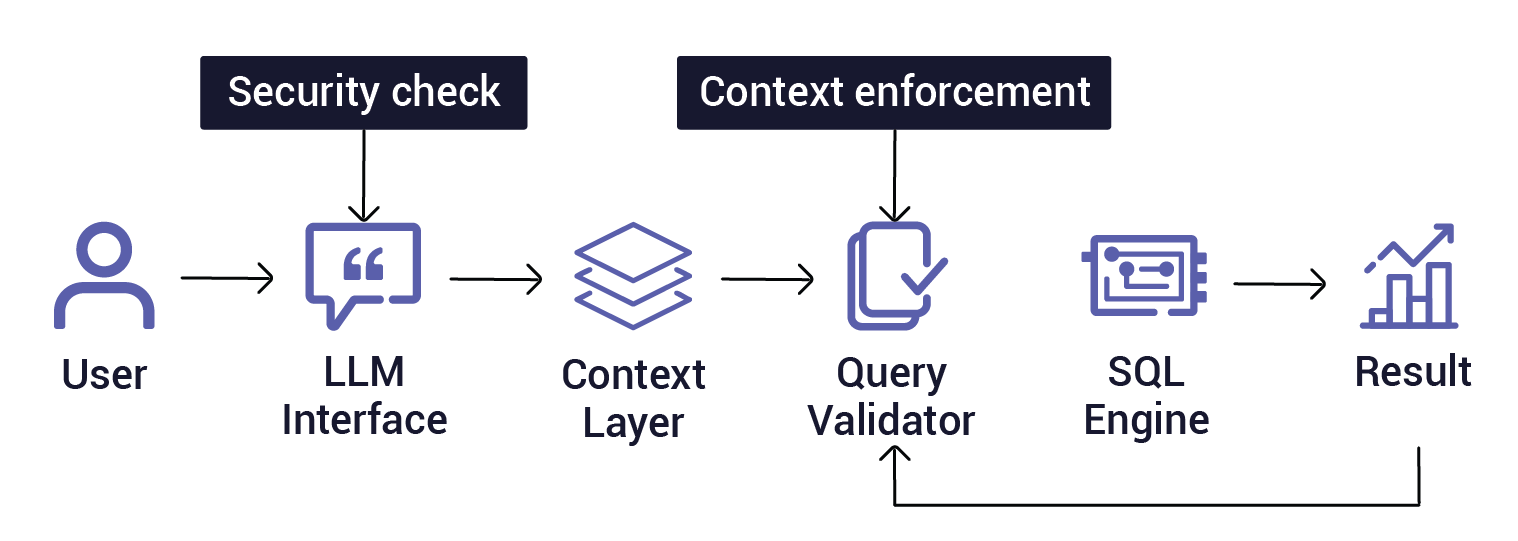
Democratization of data does not mean working against BI teams. Rather, it means accelerating access to governed, high-quality insights where a new dashboard does not need to be created for every question.
Incorporate feedback loops into BI workflows
Traditional BI workflows regard dashboards as the product, but the modern BI environment ideally should work as a living organism. By querying, exploring metrics, and clarifying results, users generate behavior as feedback signals. These signals may be used for improving anything from semantic logic to LLM performance.
LLMs do not change spontaneously. Their performance upgrades when organizations establish explicit feedback loops and use these to retrain models, change prompts, or improve semantic mappings. The implementation of feedback loops in the BI architecture enables organizations not simply to provide answers but also to learn which are the most important questions that users want answered. They can find out what metrics confuse users and identify software gaps in the context layer.
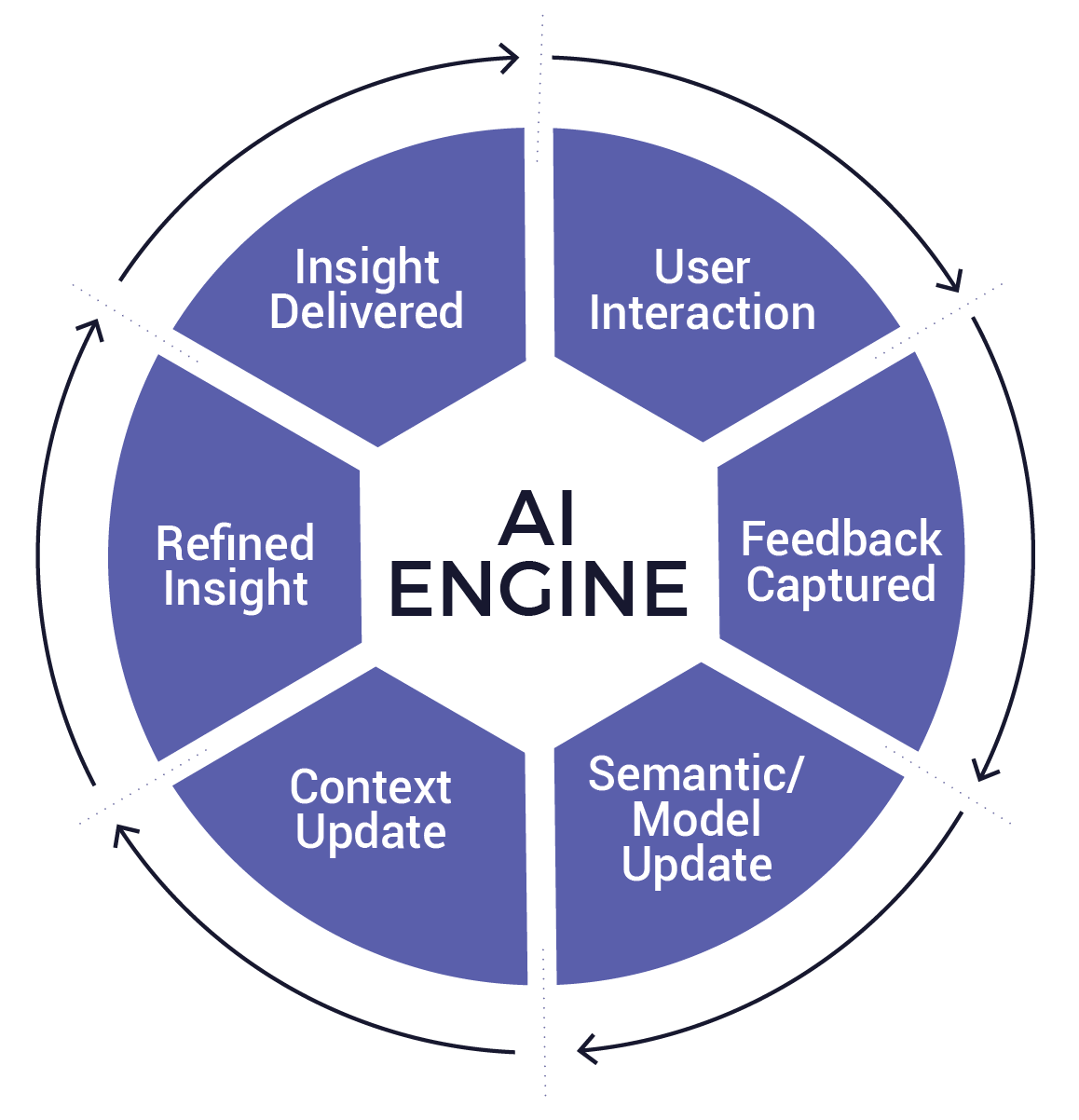
For example, if users constantly try to rephrase results for “customer churn” or reject results, the system might flag the semantic definition for further consideration or retraining. In this way, rejecting insights creates a product improvement loop.
Types of BI feedback loops
A good feedback mechanism could take many forms in business intelligence systems:
- Explicit feedback occurs when an end user flags an answer as unhelpful or requests clarification; the signal is communicated very directly that something was misunderstood.
- Implicit behavior might include requerying the same topic. Abandoning results or drilling down excessively exposes users' uncertainty or dissatisfaction with their results without them saying so explicitly.
- Some platforms may support annotation trails, where end users can tag and perhaps comment or vote on explicit metrics. Such interactions become valuable signals to those who curate the context layer.
- At a finer granularity, system logs provide insight into when the user overrides or rewrites an LLM-generated query, showing through example where the model went wrong in interpreting the intent.
How to implement feedback in BI systems
Instrumentation starts with front-end behavior, so track user interactions, be they filter changes, click-throughs, or search refinements. One can also analyze logs that show that various terms continuously receive little engagement or generate higher rejection incidence; this can help to isolate semantic mismatches.
The key factors here are to link BI users, data owners, and context layer maintainers into the same workflow established by feedback loops. Coupled with retraining cycles that use labeled interactions, organizations can use this to continuously tune both their LLMs and context layers toward the working standards of those using them.
If structured feedback becomes the input, BI systems will make great strides toward becoming smart, intuitive, and aligned with data usage by teams. By observing how users treat responses, the system can narrow down the causes behind a misunderstanding: vague metadata, weak semantic definitions, or an outright lack of business context. At the core, feedback is not just corrective input; feedback is refined, building semantic models so that it may improve answer quality organization-wide.
A modern BI environment means every question asked and every answer checked is an opportunity for learning. Such feedback loops do not merely enhance user experience but also help in bridging the gap between what the users need and what the system provides.
Where WisdomAI fits in
WisdomAI interfaces the context layer, permission modeling, and natural language querying as a single application. Rather than exposing APIs, WisdomAI supports guided, context-aware chats that are secure and intuitive to make data exploration easy and safe for non-technical users. Once a context layer is in place, WisdomAI platforms integrate a context layer, creating a bridge between structured metadata and conversational analytics.
Instead of forcing teams to build a new dashboard for every inquiry, WisdomAI lets users simply ask questions in natural language and return a secure, governed visual answer. These answers become more accurate as the embedded feedback loops help improve them over time.
The combination of semantic and contextual aspects makes WisdomAI a solution for companies to scale insights without compromising on control, clarity, or governance.
{{banner-small-3="/banners"}}
Last thoughts
Business intelligence no longer centers around creating reports and dashboards. A business intelligence strategy must evolve as a scalable architecture to support AI-based insights, enable governed self-service, and adapt to feedback.
A data maturity foundation is what allows LLMs to operate responsibly, transforming BI from a reactive tool into a proactive insight engine. By aligning BI with enterprise data strategy, developing a maturity roadmap, and creating a context layer, a solid foundation is laid for LLMs to safely operate on. Secure natural language interfaces open access to business users; the continuous feedback loop allows the system to learn and improve in quality over time.
A change is not a choice but a way to progress. BI teams must evolve beyond report builders and actualize themselves as insight enablers while thinking strategically.